Кто есть кто в джедайском старте, или Как я учился анализировать естественную речь
В общем, дело было так: уже пару месяцев я активно обучаюсь методам статистического анализа. Сначала я делал это методом «научного тыка», потом более академично, с использованием книг, разработав себе программу обучения. Разбираюсь в коде Пайтона, параметрических тестах и вычислительной статистике. В общем, примеряю ко всему подряд свои «аналитические» умения как могу.
Однако существует одна категория данных, которая никак не дается мне — вернее, поддается, но мне все равно сложно понять, как с ней работать. Какие библиотеки использовать, какой алгоритм анализа и т.д. Это естественный язык.
И вот в первых числах января «подвалило» счастье, а именно очередная порция данных от участников нашего спринта.
У нас есть традиция: каждый новый спринт рассказывать о себе. Кто-то в Новый год ходит в баню, а мы вот рассказываем о себе. Так случилось и в этот раз: прислали мне 118 ответов участников нашего трехмесячного марафона, в которых они говорят, кто они, зачем сюда пришли, и описывают уровень их джедайской зрелости (который мы измеряем, спросив, читали ли они книгу или нет, пробовали ли какие-то техники). Что у них получается хорошо, а что нет. В общем, ответы — «та еще история в нескольких актах». Читать интересно, но как анализировать — непонятно.
Подобные опросы-«представления» существуют в первую очередь для того, чтобы участники малых групп знали, с кем в компании они оказались. Ну и в целом банально вежливо представиться перед трехмесячным путешествием по пустыне продуктивности. Пустыня она еще и потому, что многие современные профессионалы являются выгоревшими профессионалами. Да, если что, и на это утверждение у нас тоже есть что «предъявить». Мы все анализируем. Но вернемся к насущному опросу.
Немного деталей:
Дата проведения: 1–7 января 2026 года
Место: онлайн с помощью бота.
Форма: сообщение с тегом “осебе”
Содержание: имя, возраст, увлечения, читал «Джедайские техники» или нет, пять слов о себе, какая цель на марафон.
Из формата опроса можно догадаться, что он крайне шумный и вообще никак не структурированный. То есть для того, чтобы понять, что нам написали, нужно прочитать 118 ответов объемом от 50 до 250 слов. Текст мало прочитать, его еще нужно проанализировать, а человек, мягко говоря, сомнительное средство анализа. Во-первых, потому что интерпретировать каждый будет по-разному, а во-вторых, интерпретации даже одного и того же человека будут отличаться в зависимости от его состояния. Другое дело компьютер: математика не ошибается, и железка не устает. Поэтому средствами анализа стали: Python, Marimo notebook, FastText (векторная модель эмбеддингов), гибридная классификация (ручная подстановка слов) ну и всякие средства визуализации, например векторов, и всякие прочие plot’ы.
Перед тем как сказать, что FastText и векторный анализ для малого объема текста — это чересчур, я сам скажу: да, чересчур. Но очень уж мне хотелось попробовать эту вундервафлю, и мне понравилось.
Немного о том, зачем такой анализ нам нужен: мы хотим наглядно показать всем, кто записывается в «младшую» программу, что в этом нет ничего особенного и возвращаться, так сказать, к истокам, пересматривать свою систему является нормальной практикой. Спойлерну: нам это удалось. В младшей программе всего 48% новичков, 52% — это те, кто пробовал, пытался что-то сделать, у кого уже имеется система и он просто хочет ее «пересмотреть», обновить и так далее.
Теперь к тому, как выглядел весь процесс.
Загадка
Первой и самой большой сложностью является то, что данные ненадежные. Когда джедай говорит, что владеет «силой», он представляет себя магистром Йодой, ну, на худой конец, Оби-Ваном, тогда как на самом деле он еще падаван.
Джедай первого уровня может написать «Я прочитал книгу» или «Что прочитал, но в книге ничего особенного, суть можно сформулировать одним предложением», предполагая безграничное владение «силой». В то время как джедай второго или третьего уровня напишет: «моя система рухнула», подразумевая неудачу. Хотя формулировка «моя система рухнула» говорит о компетенции значительно больше, чем «я прочитал книгу». Когда что-то рушится — это значит, что как минимум была или есть попытка систематизировать задачи, проекты, расписание в календаре.
Именно потому, что речь «многогранна» и «многосмысленна», нам и нужен математический способ «вскрыть» смысл написанного и классифицировать всех 118 джедаев джедайского старта от первого уровня (который в моей математике стал нулевым) до пятого (который превратился в четвертый) без «ручного» чтения.
Однако прочесть все равно пришлось, потому что 34 джедая удалили или модернизировали эмодзи, которые я планировал использовать для «вырезания» текста, предполагаемого к анализу (находившегося между двумя эмодзи 🪴...🎯).
Методология, или Балет в трех актах
Пайтон, блокнот Маримо и всякие библиотеки стали моей любимой игрушкой последних месяцев. Поэтому написать простой скриптик я считаю скучным — мне хочется ковыряться с новыми игрушками как можно дольше и как можно «извращенней». Имея такое желание, решил я построить фильтр из стоп-слов, ИИ-векторов и уникального набора ключевых слов, на который направлю векторы.
Вообще сначала была идея использовать только лишь ИИ, но фокус не удался: у меня получалось от 70 до 90 джедаев с сомнительной «ориентацией» — то ли первый уровень, то ли пятый. Разброс конский, поэтому пришлось включать двухуровневую фильтрацию.
Акт первый. Векторное пространство
Для «создания» векторного пространства я использовал открытую модель FastText, которая превращает слова в 300-мерное пространственное поле. Как это работает — ХЗ, но как-то работает. Идея заключалась в том, чтобы слова с одинаковым смыслом соотнести с якорями (о них в следующем абзаце). Например, в 300-мерном пространстве слова «хаос» и «бардак» находятся рядом, а в нашем контексте несут одинаковый смысл.
Далее к каждому уровню джедайства нам нужно было «наколхозить» некоторый набор ключевых слов, за которые векторы зацепятся. Я пробовал разные варианты, от относительно простых:
Простые якоря
“Level 0 (Newbie)”: “Я не читал книгу, не читала, даже не слышал про это. Я только начинаю, нет опыта.”
“Level 1 (Failed)”: “Я пробовал, пытался применять, но не прижилось. Я бросил, система развалилась.”
“Level 2 (Theorist)”: “Я читал обе книги, знаю теорию, смотрел видео. Знаком с материалом, но практики мало.”
“Level 3 (Stressed)”: “Я периодически возвращаюсь к системе. Работает со скрипом, наплывами. Часто все ломается, происходят срывы.”
“Level 4 (Solid)”: “Я пользуюсь системой давно. Она активно работает. Я все внедрил, хочу только укрепить и улучшить.”
До навороченных, где по три предложения на один уровень:
Пример множественного якоря первого уровня джедайства
“Level 0 (Newbie)”:
“Я совсем новичок, ничего не знаю, даже не слышал.”
“Книгу не читал, систему не строил, полный ноль.”
“Только начинаю погружаться, нет никакого опыта.”
Но ни один не выдавал результат, при котором джедаев с «сомнительной» ориентацией было бы меньше 60, а этого, как бы, очень много на выборку в 110 касок. Когда я начал разбираться, почему так происходит, то заметил, что векторы ломаются на следующих предложениях: «Я не читал книгу» и «Я читал книгу».
Математически эти два предложения в 300-мерном пространстве находятся очень близко друг к другу. FastText понимает суть предложений, но не понимает «негативную коннотацию».
Ладно, подумал я, сейчас мы «извратимся», и пошел колхозить классификатор.
Акт второй. Как я построил Киборга
Чтобы как-то развеяться и взбодрить мозг, я пошел смотреть «Добро пожаловать в Дерри». Ужасы Пеннивайза помогли. В результате я решил разделить ответственность: оставить ИИ (художнику) 300-мерное векторное пространство и способность работать с абстрактными словами и понятиями, такими как «стресс», «привычка», «состояние потока», но при этом создать правило поиска специфических «свидетельств», например словосочетания «не читал» и слова «забросил». Правило простое: если в тексте есть слово или словосочетание, которое откровенно указывает на то, что человек «определенного» уровня, ИИ, работающий с абстракцией, не включается, и джедая классифицируют в соответствии с правилами.
Получилось, что половина джедаев была рассортирована ИИ, в то время как другая — набором правил. А теперь пора проверить, правильно ли они рассортированы.
Акт третий. Проверка
Вопрос проверки, всё ли у нас верно, стоит как нельзя кстати. Мне сложно понять, что измерять, и поэтому я взял на себя смелость обратиться к ИИ с моим запросом и попросить помочь проверить получившийся результат. Решение мы нашли: у нас будет одна визуальная, другая интуитивная проверка.
Для простоты я попробую привести аналогию школьной столовой и детей разных классов: начальная школа, средняя и старшая. Если я как дежурный буду стоять в столовой, мне практически невозможно определить, кто с кем находится, для меня это будет месиво из детей. Но если я поднимусь на этаж выше и посмотрю, как дети передвигаются, то смогу легко выяснить, какие классы где находятся. Потому что старшие дети могут передвигаться самостоятельно, а младшие — под присмотром классного руководителя. Дальше — больше: если приглядеться к старшим детям, среди них можно безошибочно распознать, кто чем увлекается, какое им свойственно поведение и так далее.
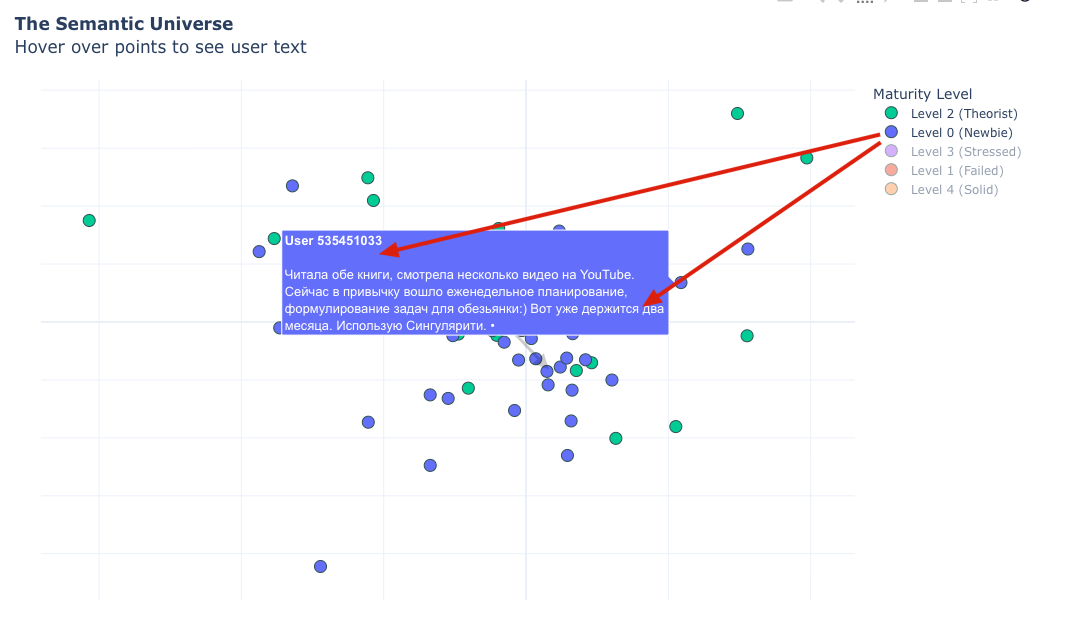
То же самое мы сделаем с 300-мерным пространством ИИ: мы расположим джедаев по уровням и посмотрим, какие «кучки» они образуют и получается ли «движение» от первого до пятого уровня, в смысле — как будут расположены кластеры.
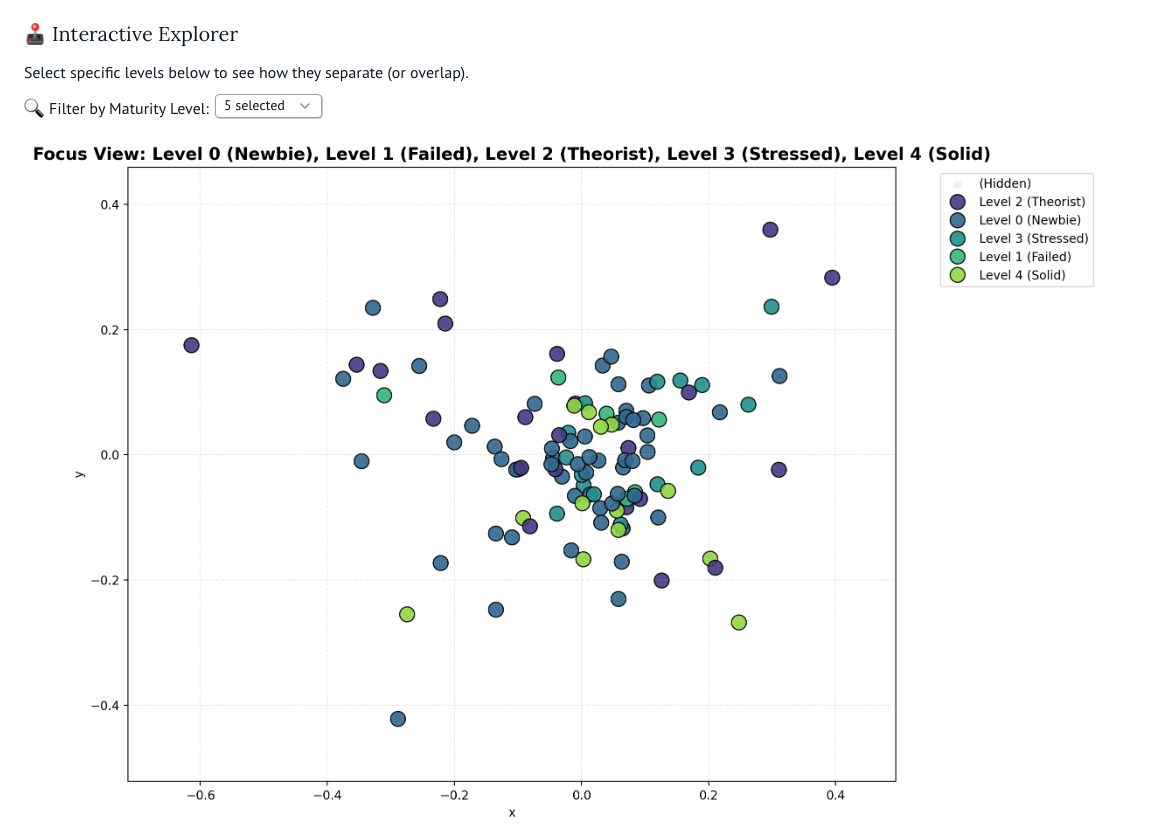
Если детально анализировать карту выше, то можно заметить, что у нас на самом деле не 5 уровней, а три.
Помните якоря, которые мы «устанавливали» во время первого акта? Всё, о чем дальше пойдет речь, связано именно с ними.
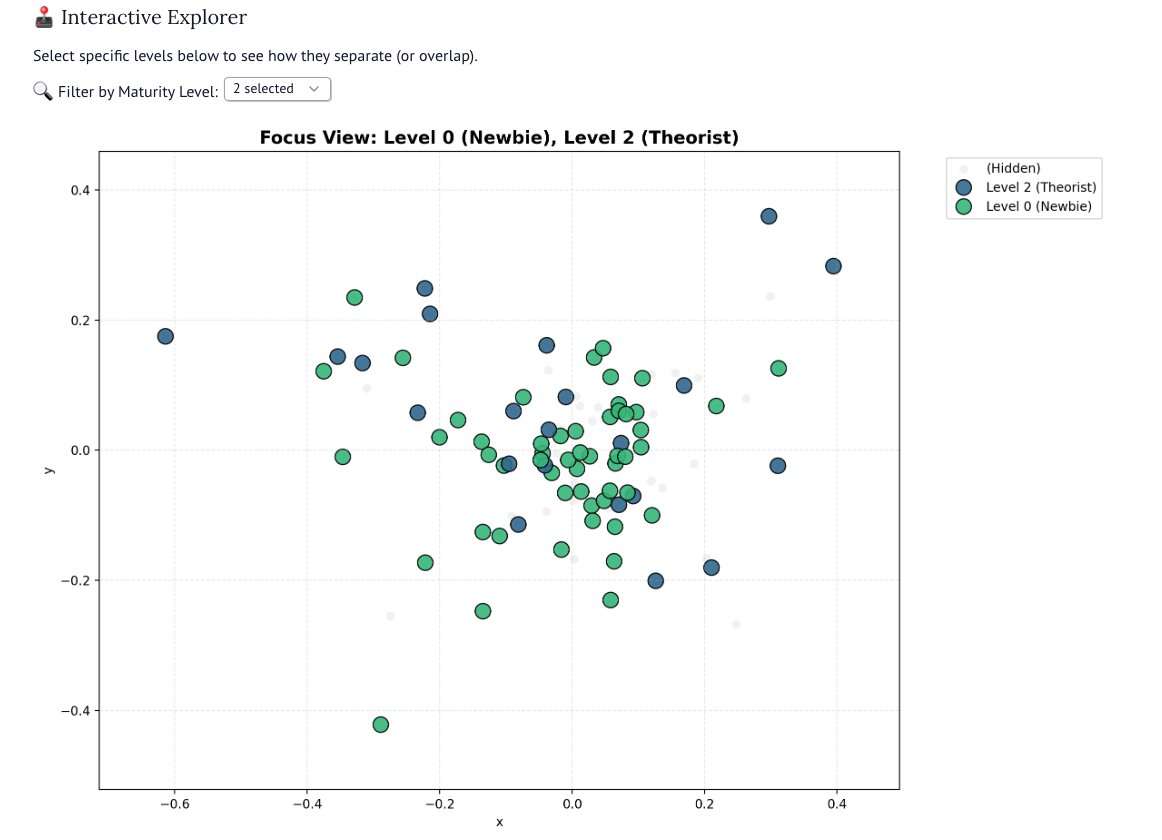
Первый, второй и третий уровни (нулевой, первый и второй) джедайства характеризуются словами: читал, книга, видео, хочу. Семантически первый-третий уровни очень близки друг к другу, а математически (если оценивать по векторам) идентичны. Джедаи первого уровня говорят «Я купил книгу» или «Я хочу прочесть книгу», джедаи третьего уровня — «Я прочел книгу». И у первого, и у второго уровня одинаковый шаблон поведения: потребление контентика, который создает иллюзию понимания. Оба уровня сосредоточены на информации, а не применении, иначе говоря, они пока еще «туристы» в мире продуктивности.
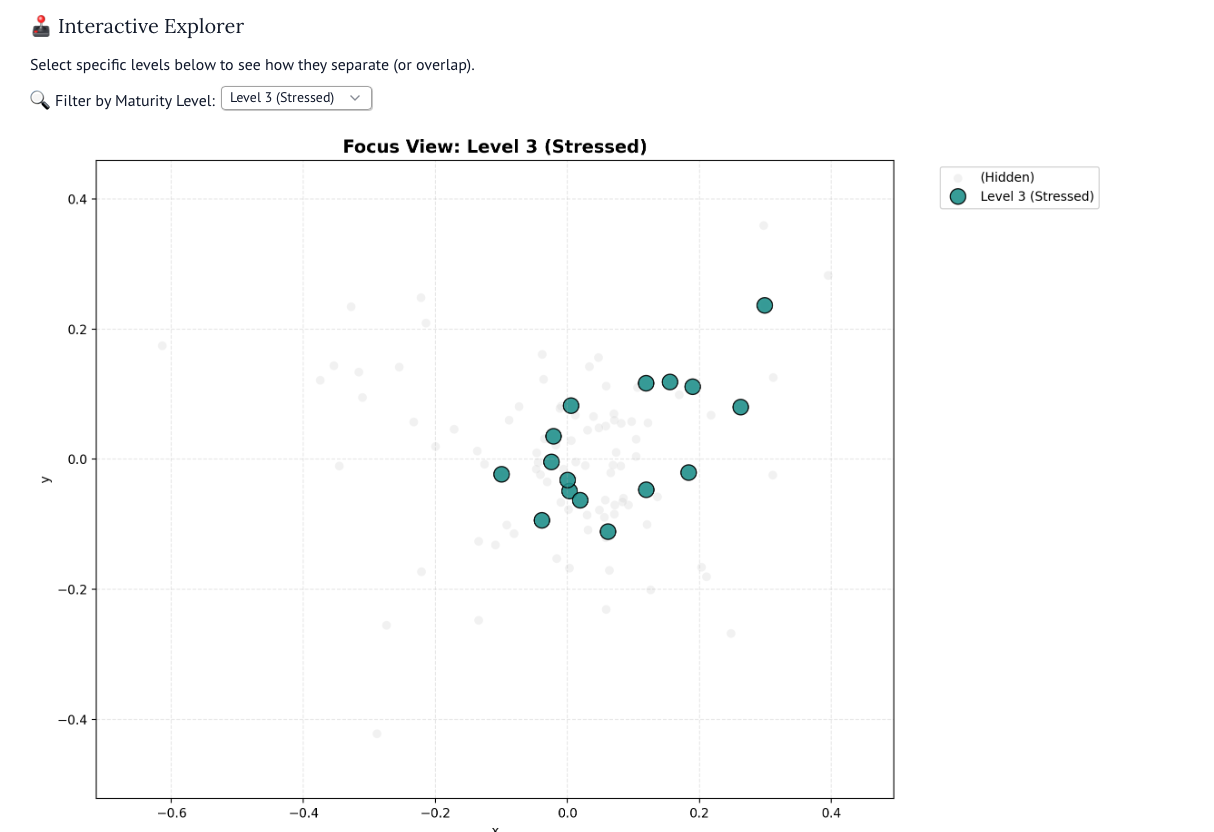
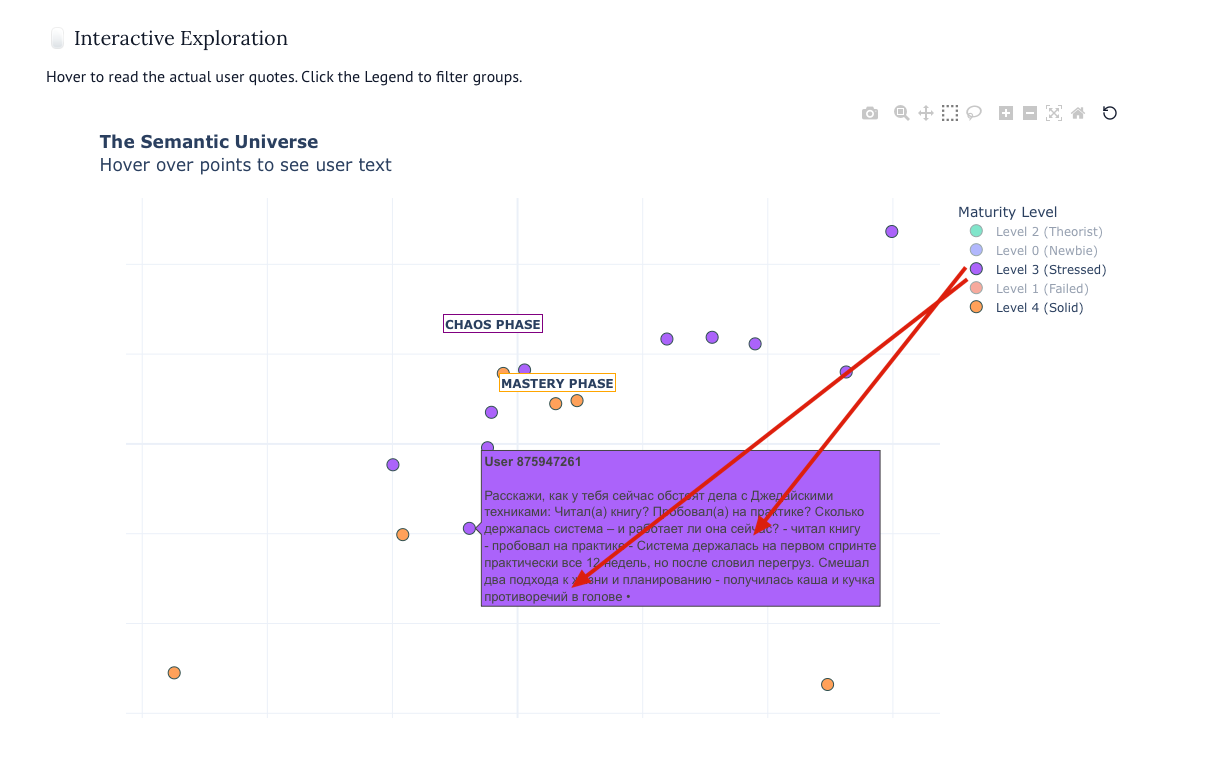
Четвертый уровень — это немного уже иное, тут слова начинают изменяться: периодически, держаться, частично, возвращаюсь. Я бы сказал, что четвертый уровень — наиболее критичный. Обратите внимание, как изменились слова: от существительных к глаголам. Книга, видео, хочу → держаться, частично, возвращаюсь. Если читать ответы четвертого уровня, то можно подумать, что у них неудача за неудачей, однако это не так. Их неуспех — это индикатор того, что они действуют; они перестали читать, а пытаются действовать, вооруженные новым знанием. Нельзя «всё развалить», если не построить в начале.
Пятый уровень, тут словарь еще больше трансформируется: работает, внедрил, стабильно, задачи. Я бы называл этот словарь «скучным», здесь минимум эмоций, нет превозмогания, борьбы. Например, слово «работает» у них появляется шесть раз, слово «стабильно» два раза. Они перестают думать о техниках, вакцинах и индикаторах и начинают — о проектах, задачах и прочем джедайском.
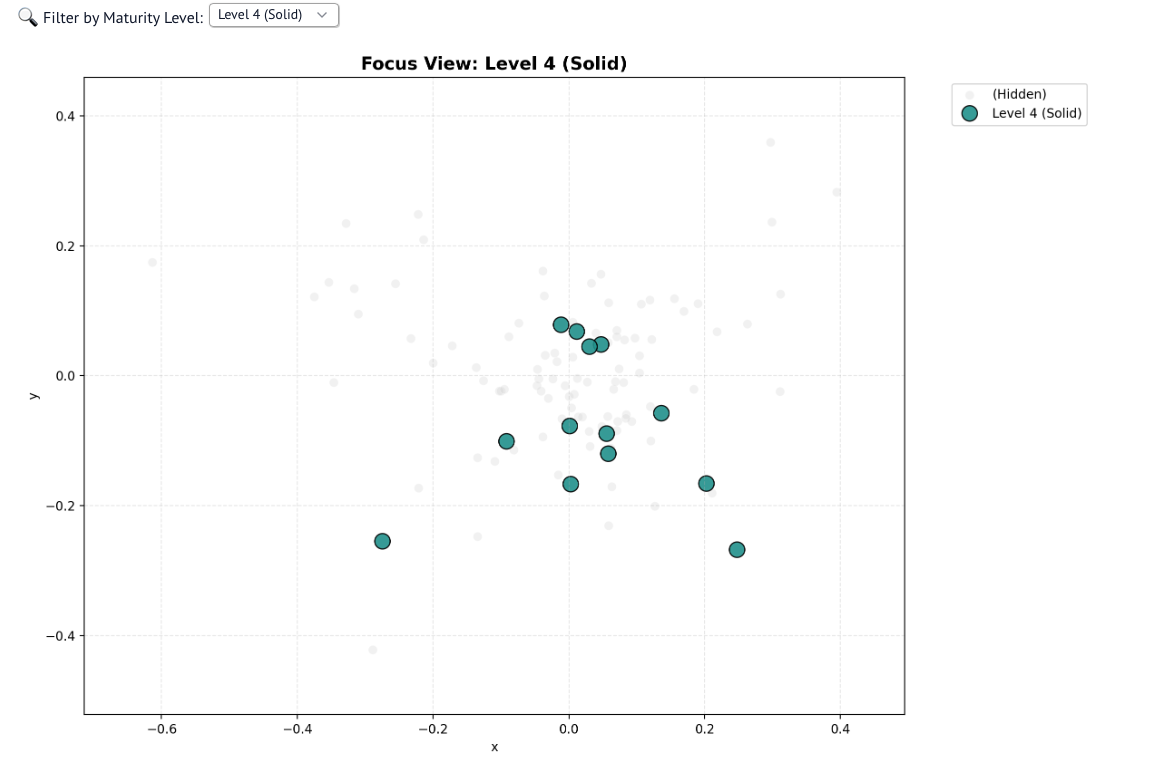
Почему когда все развалилось – это успех
Я бы сказал так: если у вас «все развалилось», то вы на верном пути. Сейчас поясню почему. Наша семантическая двумерная карта 300-мерного векторного пространства наглядно показывает, как учится человек. Разрыв между «знаю» и «умею» существует. То, что первый, второй и третий уровни пересекаются, явно об этом сигнализирует. Даже если у нас есть интеллектуальные компетенции (то есть мы знаем что-то), это не трансформируется автоматически в поведенческие компетенции. Иными словами, даже если запомнить наизусть все вакцины из «Пути Джедая» и говорить правильные слова, когда вам задают вопросы, математический анализ произнесенных или написанных слов выдаст в вас падавана, а не джедая.
Другое открытие для меня не совсем открытие, но все-таки приятно получить этому математическое подтверждение: стресс — это не баг, а фича. Если посмотреть на джедаев четвертого уровня (тех, кто возвращается и у кого что-то частично держится), то по карте они «разбросаны» между уровнями. Я бы сказал, что Путь Джедая лежит через хаос, страдание, неуспехи и возвращение в начало. Поэтому даже те, кто считал, что построил свою систему управления делами, но пришел в «старт», находятся на верном пути. Пути Джедая.
Мастерство молчаливо. Вроде как поэтично, но на самом деле так и есть: джедаи пятого уровня избегают эмоциональных слов, вместо «надеюсь», «пытаюсь», «хочу» они используют глаголы действия — «работает», «внедрил».
Очень важное послесловие
Друзья, как бы похоже на правду все сказанное выше мне не казалось, датасет очень маленький, грязненький, и векторы на таких «крошечных» объемах текста не строят. Но этот эксперимент, пусть не самый чистый, помог увидеть новую для меня грань, как еще можно анализировать естественную речь и в целом шумные данные.
А мы будем, скорее всего, этим заниматься и в какой-то момент сможем подобрать алгоритм и инструменты, которые смогут точнее обучать наших джедаев.
Постскриптум
Я немного поигрался с визуализацией данных и, чтобы не быть голословным, покажу вам, что пишут джедаи разных уровней и где они расположены на карте.
Важно: движение к «мастерству» — это перемещение с левого верхнего в правый нижний угол карты, как у нас ровно и получается.



BIO
🧠 theBrain mapping
ID: 202601091244 Source:: Friend:: Child:: Next::
Keywords:
Reference: